一、 快速排序的核心原理
快速排序本质上是分治法(Divide and Conquer)的经典应用:
- 任取序列中的一个元素作为枢轴(Pivot),将序列中剩下的元素与其进行比较:比枢轴小的元素放在一侧,比枢轴大的元素放在另一侧(与枢轴相等的元素放在任一侧均可)。
- 对被枢轴分隔开的两个子区间继续挑选枢轴,递归地执行上述划分操作,直到区间为空或仅剩1个元素时停止排序。
二、 最常用的原地工作形式(双指针法)
在实际写题和应用中,我们通常默认采用原地工作(In-place)的形式来节省空间。核心思路是“谁不空,谁比较,谁移动”:
- 初始化:把作为起始枢纽的元素(通常为列表的首部或尾部元素)赋值给变量
pivot,此时原枢纽元素因为已经有了拷贝,其位置可以被视为“空出”。同时,设立两个指针left和right分别指向待排序列表的两端。 - 比较与移动:将另一端指针(不指向空缺位置的指针)所指的元素与
pivot进行比较。- 若满足交换条件(赋值):将该元素填入另一侧的空缺位置中,对应被赋值位置的指针向列表内侧推近一步,而刚刚移走元素的位置则成为了新的“空缺”。
- 若不满足交换条件(不赋值):当前指针继续向内侧推近一个单位地址。
- 枢轴归位:不断重复上述步骤,直到
left和right指针相遇(指向同一个地址)。此时的位置即为枢纽元素的最终正确位置。将pivot赋值到该处,枢纽元素归位,本轮划分宣告完成。
注意:如果
pivot初始指向的不是区间的第一个元素,在操作前通常需要先将其与第一个元素互换。快排的趟数和枢轴的选取息息相关,本质上取决于划分是否对称。
三、 快速排序的复杂度分析
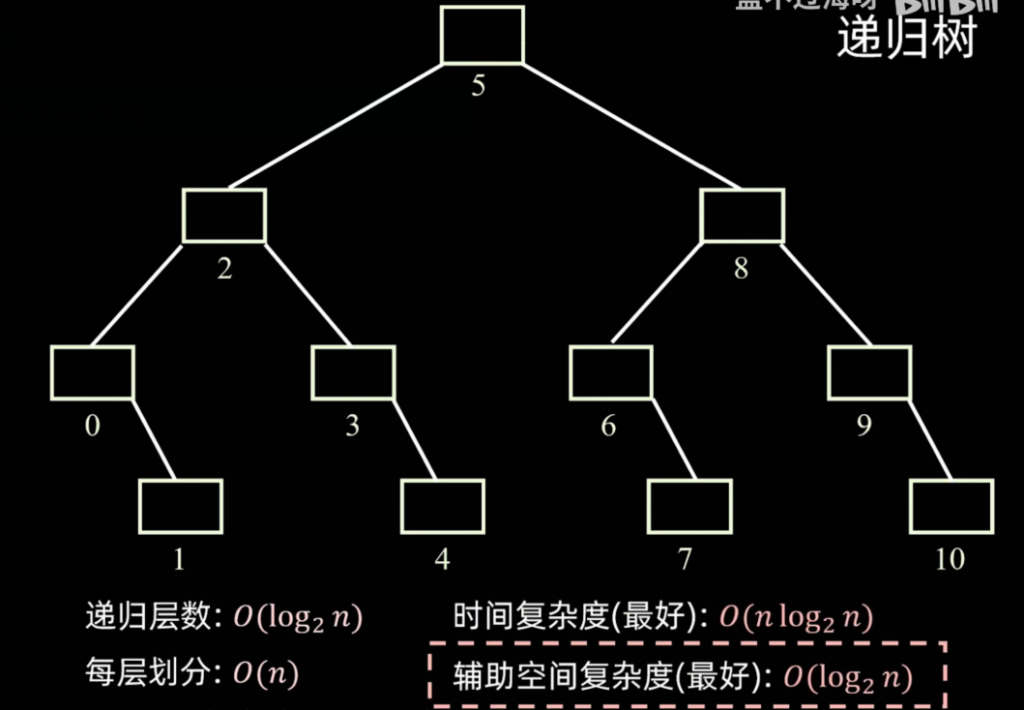
快排的性能极大地依赖于每次枢轴划分的平衡程度。我们可以借助递归树来进行直观的分析:
1. 最好情况(极其平衡)
- 场景:每次划分区间都完美地左右等长。此时的递归树呈现为一棵平衡的完全二叉树。
- 时间复杂度:
- 递归层数(即区间划分次数)类似折半查找,为 O(\log_2 n)。
- 每层的元素划分操作需要遍历当前层的所有元素,耗时 O(n)。
- 总时间复杂度:O(n \log_2 n)。
- 空间复杂度:递归过程需要系统栈来存放等待结果的函数。由于递归层数为 O(\log_2 n),所以辅助空间复杂度最好为 O(\log_2 n)。
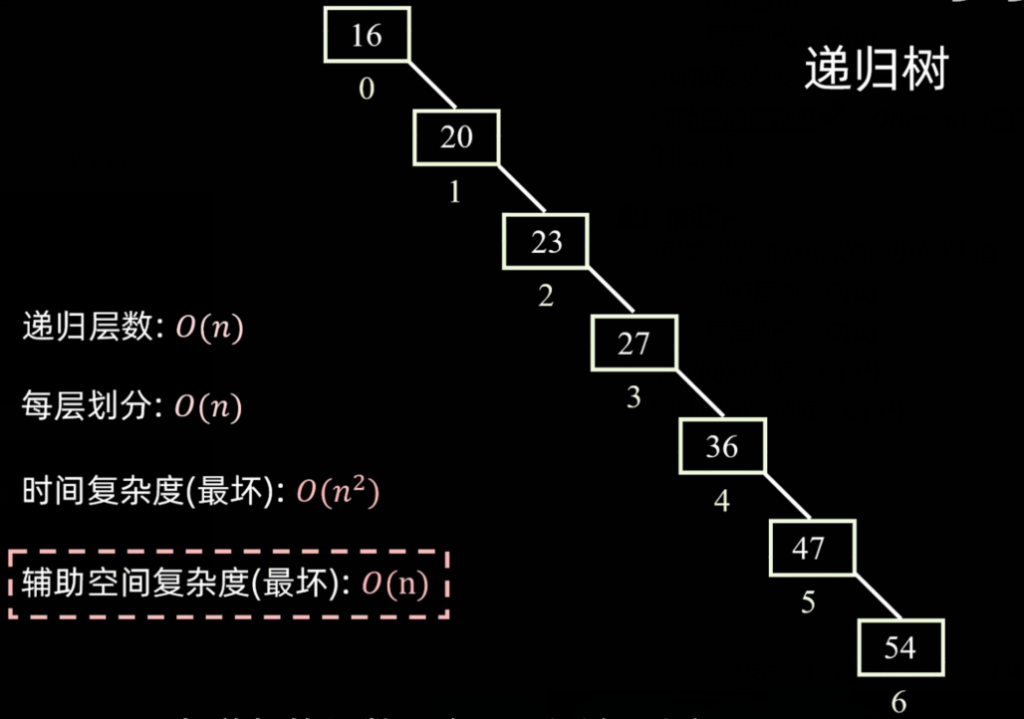
2. 最坏情况(极端倾斜)
- 场景:每次选择的枢纽恰好都是当前区间的最小值或最大值,导致区间完全不平衡(例如原本就是有序的序列)。此时的递归树退化成了一条单链表。
- 时间复杂度:
- 递归层数增加到了 $O(n)$。
- 每层划分依然需要 $O(n)$。
- 总时间复杂度(最坏):退化为 $O(n^2)$。
- 空间复杂度:由于递归调用栈深度达到了 $n$ 层,辅助空间复杂度最坏为 O(n)